Originally published: 14/05/2019 10:03
Publication number: ELQ-92419-1
View all versions & Certificate
Publication number: ELQ-92419-1
View all versions & Certificate

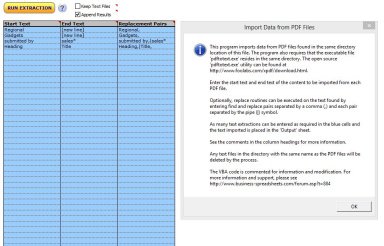
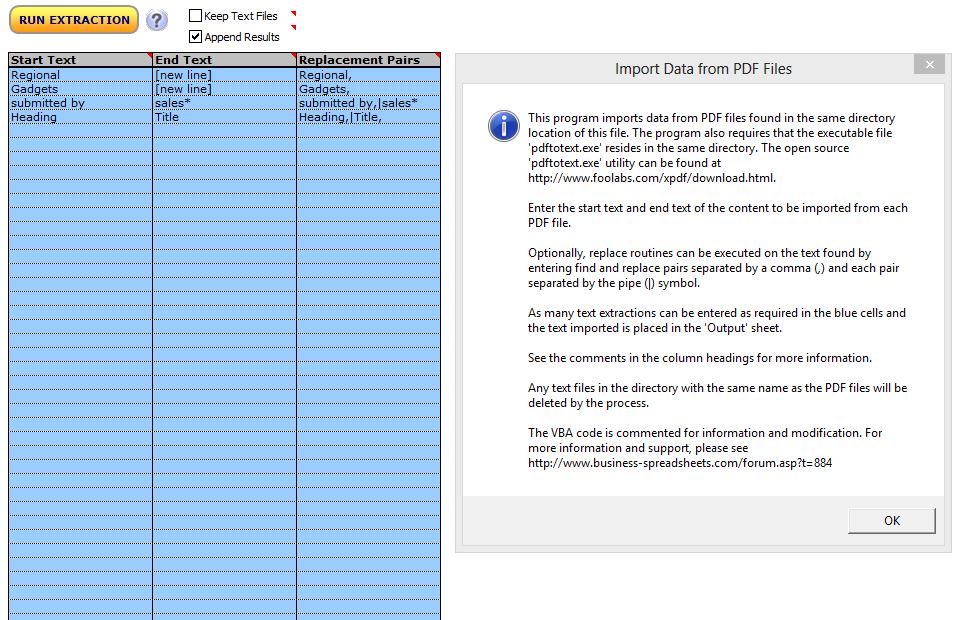
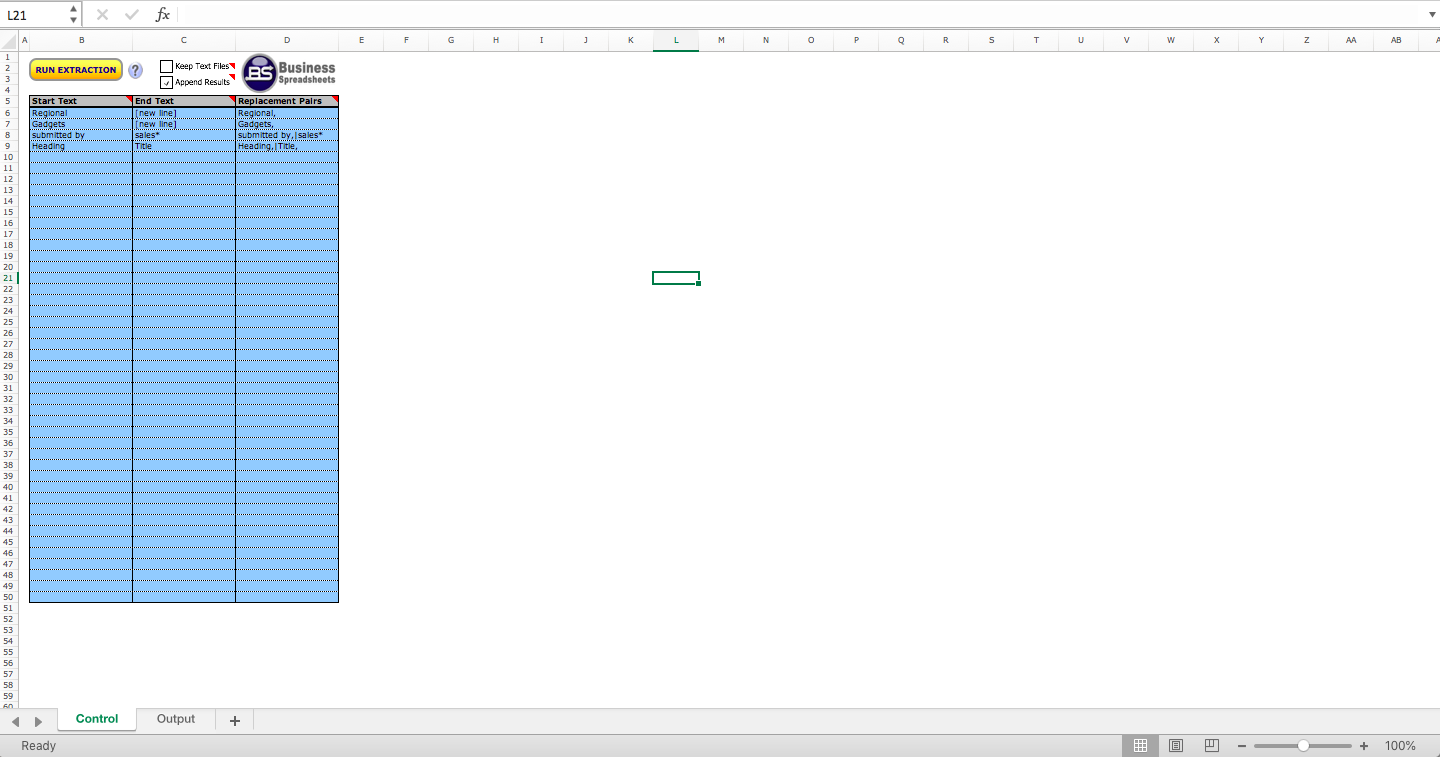
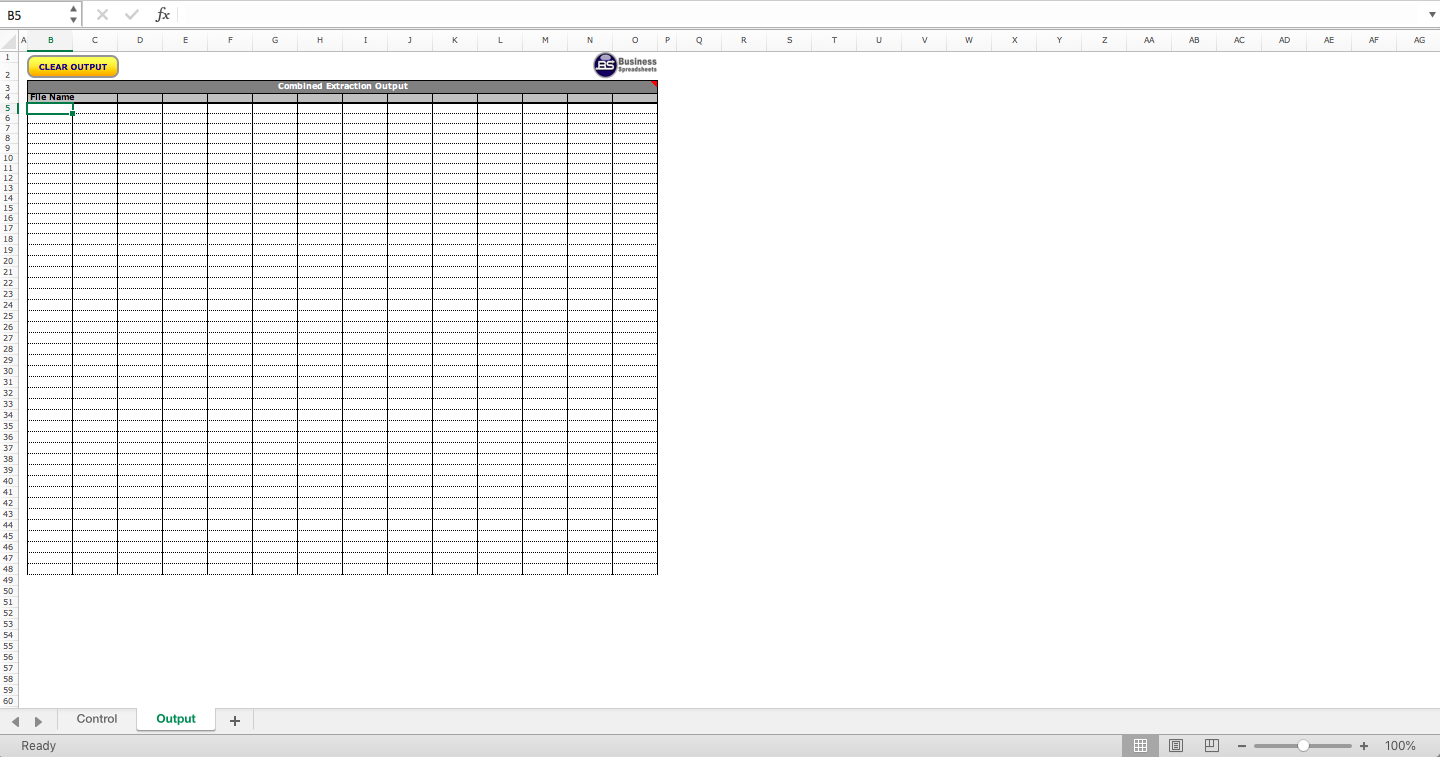
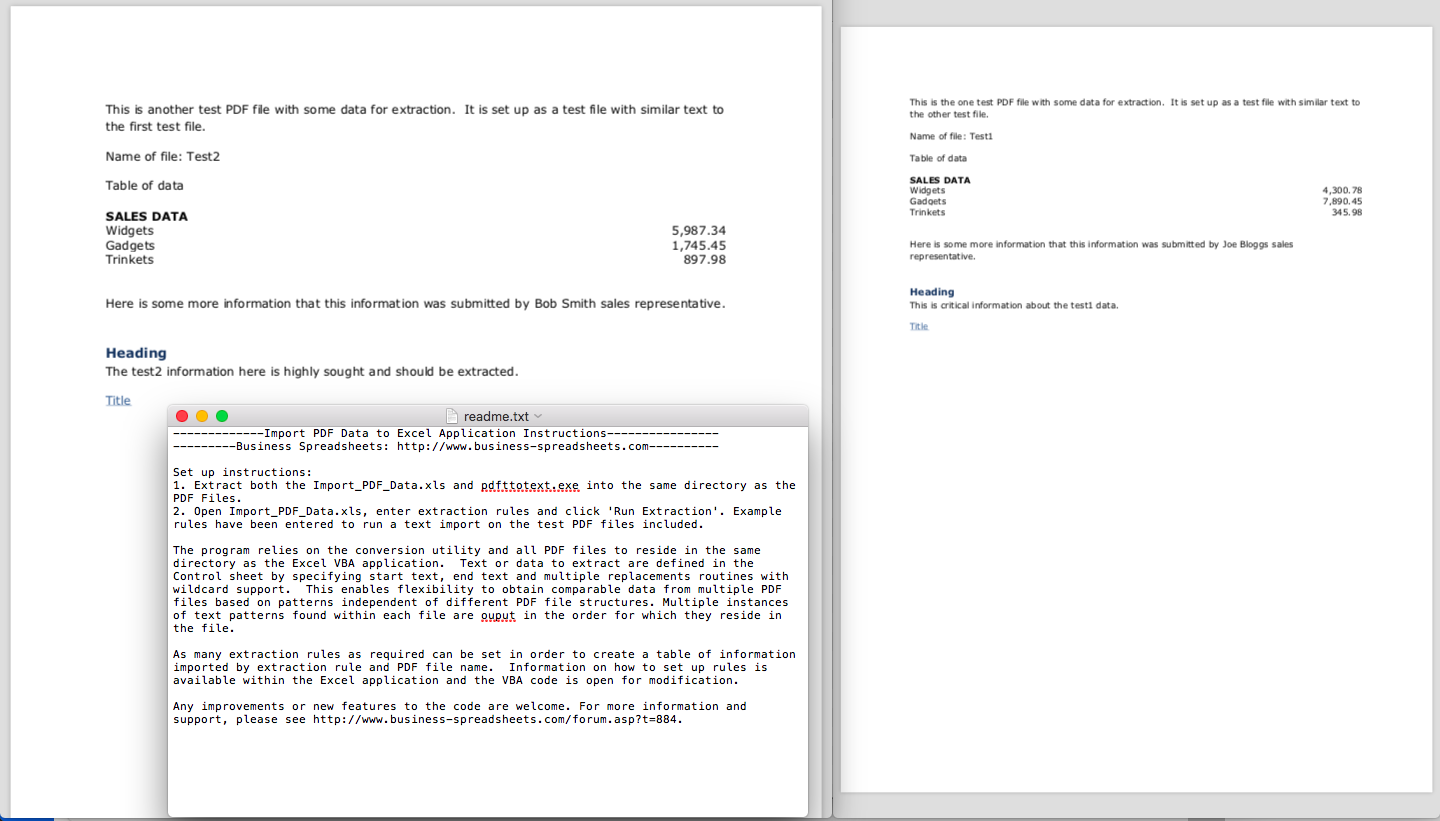
Batch PDF Data Extraction
Extract text and data from multiple PDF files into structured tabular format based on start and end pattern matching.
Purpose built Excel solutins for business and finanacial decision makingFollow 183
Business Spreadsheets offers you this Best Practice for free!
download for free
Add to bookmarks
Further information
Extract multiple data streams from similarly structured PDF files into a structured table
Many PDF files require the same data to be extracted for subsequent use and analysis
Scanned PDF files or PDF files that are not able to be converted to plain text.
