


Originally published: 09/01/2018 14:26
Last version published: 02/03/2018 14:31
Publication number: ELQ-42427-2
View all versions & Certificate
Last version published: 02/03/2018 14:31
Publication number: ELQ-42427-2
View all versions & Certificate

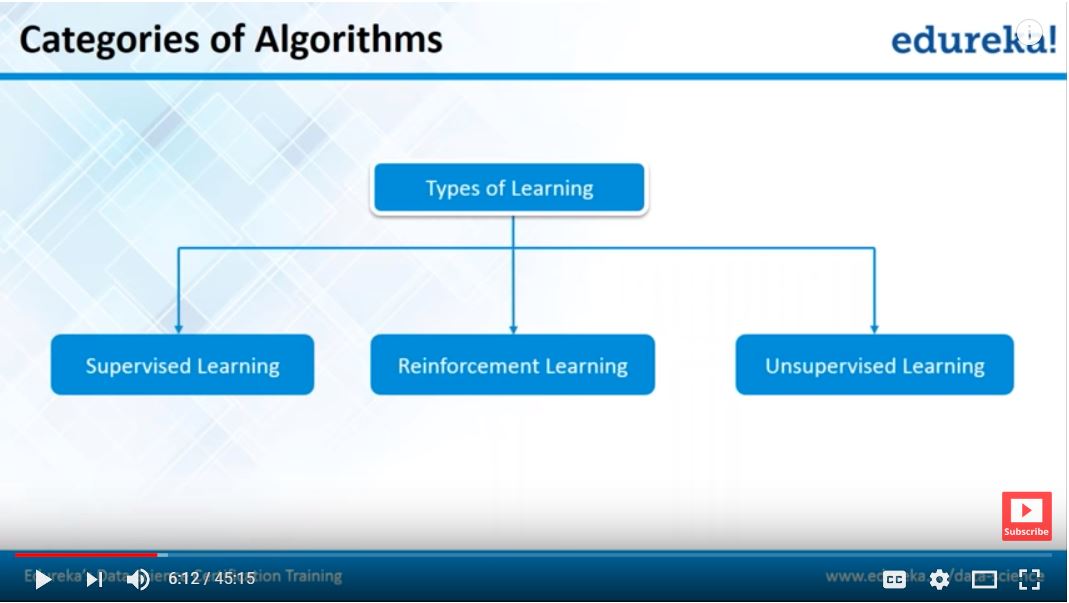
Building Robust Machine Learning Models
This presentation focuses on the fundamentals of building robust machine learning models.
Add to bookmarks
Did Data Science Dojo's Best Practice help you? You can make a small financial contribution to support the author.
helpSupport
